Loading content...
Table of Contents
Back to all internships
Data & AI Engineering
Vlaamse Radio- en Televisieomroeporganisatie (VRT)
Blvd Auguste Reyers 52, 1043 Brussel
January 2023 - March 2023
DBTPythonAWSJupyter NotebooksHuggingfaceLangChainPostgres with Pgvector
Overview
Conducted an in-depth feasibility study on leveraging advanced large language models (LLMs) for automating the generation of DBT (Data Build Tool) documentation, addressing VRT's undocumented DBT codebase.
Experience Details
Overview
Conducted an in-depth feasibility study on leveraging advanced large language models (LLMs) for automating the generation of DBT (Data Build Tool) documentation, addressing VRT's undocumented DBT codebase. dbt is an open-source command-line tool designed for data analysts and engineers to collaboratively develop, test, and deploy data transformations.
1. Introduction
In this project, I explored the feasibility of using Large Language Models (LLMs) to document dbt (data build tool) queries and implemented a solution tailored to the VRT data team's needs. dbt is an open-source command-line tool designed for data analysts and engineers to collaboratively develop, test, and deploy data transformations.
2. The Problem
The VRT data team maintained a large dbt project with numerous models, packages, and macros, but lacked documentation. This made it difficult to understand and maintain queries. My goal was to determine if LLMs could generate clear, accurate documentation for both technical and non-technical users.
3. Research Phase and Initial Explorations
Model Selection and Evaluation
- CodeLlama-7b-hf: Trained on code, valuable for interpreting SQL-based dbt queries
- Llama 2-7b-Chat & 13b-Chat: Conversational, ideal for user-friendly explanations
- Google Gemma 7B: Strong in text summarization and Q&A
- Mistralai/Mixtral-8x7B-Instruct-v0.1: Excellent at following instructions
Inference and Challenges
I ran initial inferences on Colab but faced GPU memory limits, successfully testing only Llama 2-7b-Chat. To scale, I later moved to AWS SageMaker and experimented with Hugging Face's API.
Prompt Experimentation
I tested prompts explicitly stating "dbt query" to improve responses. Complex topics like multi-join explanations required multi-step prompting, highlighting the need for efficient strategies.
View Document
Prompt Experimentation Document
4. Implementation Approaches
Throughout these implementations, I iteratively refined the solution in collaboration with the VRT data engineers, incorporating their feedback on the generated documentation to ensure clarity, accuracy, and relevance.
4.1. Approach 1: Prompt-Based Documentation
This minimal-infrastructure approach sends prompts directly to the LLM.
- Simple to modify prompts for different dbt query types
- Challenges: token limits, prompt-quality-dependent results, no memory across queries
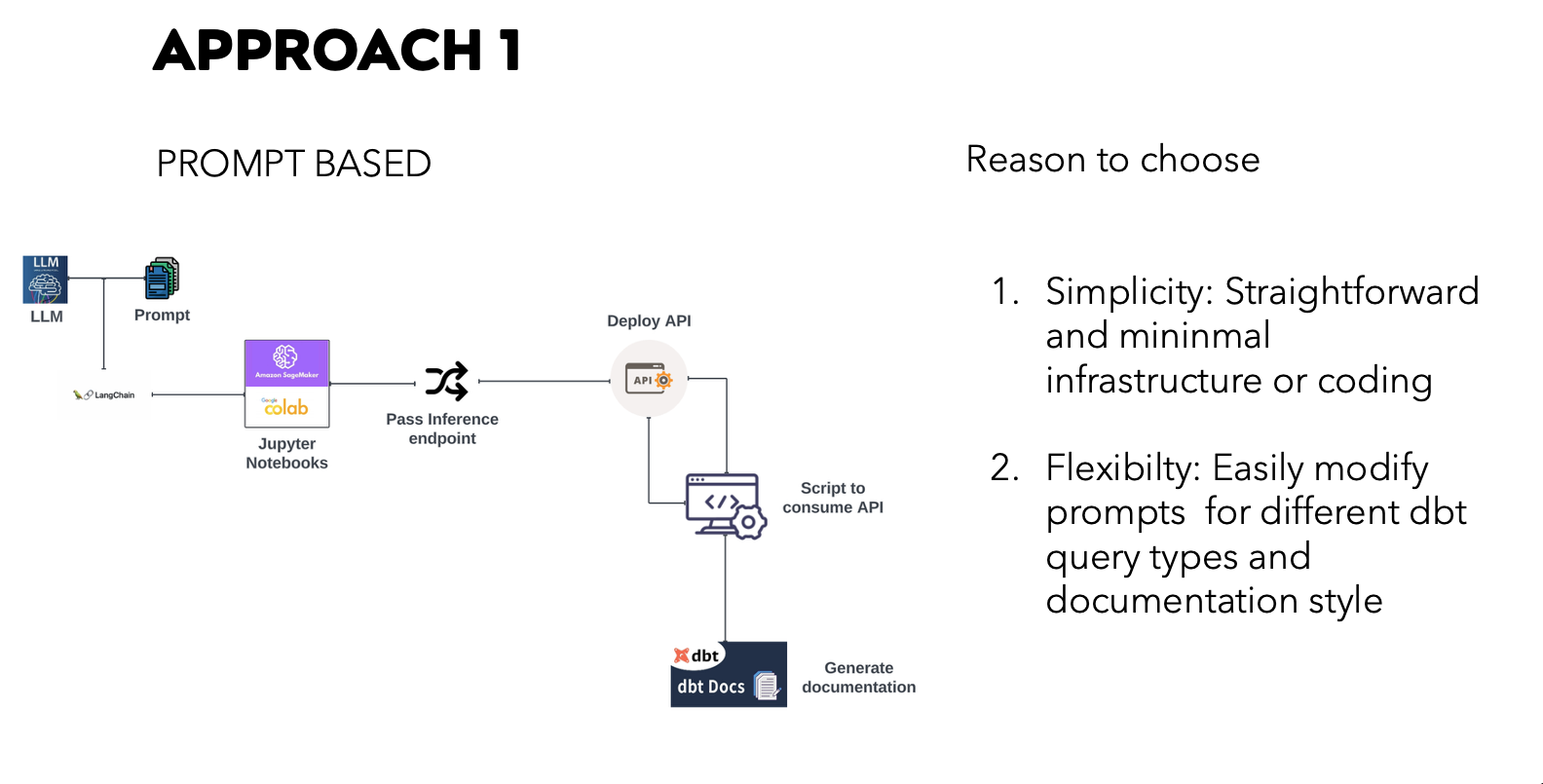
Prompt-Based Approach Workflow
4.2. Approach 2: Retrieval-Augmented Generation (RAG) using Embeddings
This approach uses embeddings and a vector store for richer context retrieval.
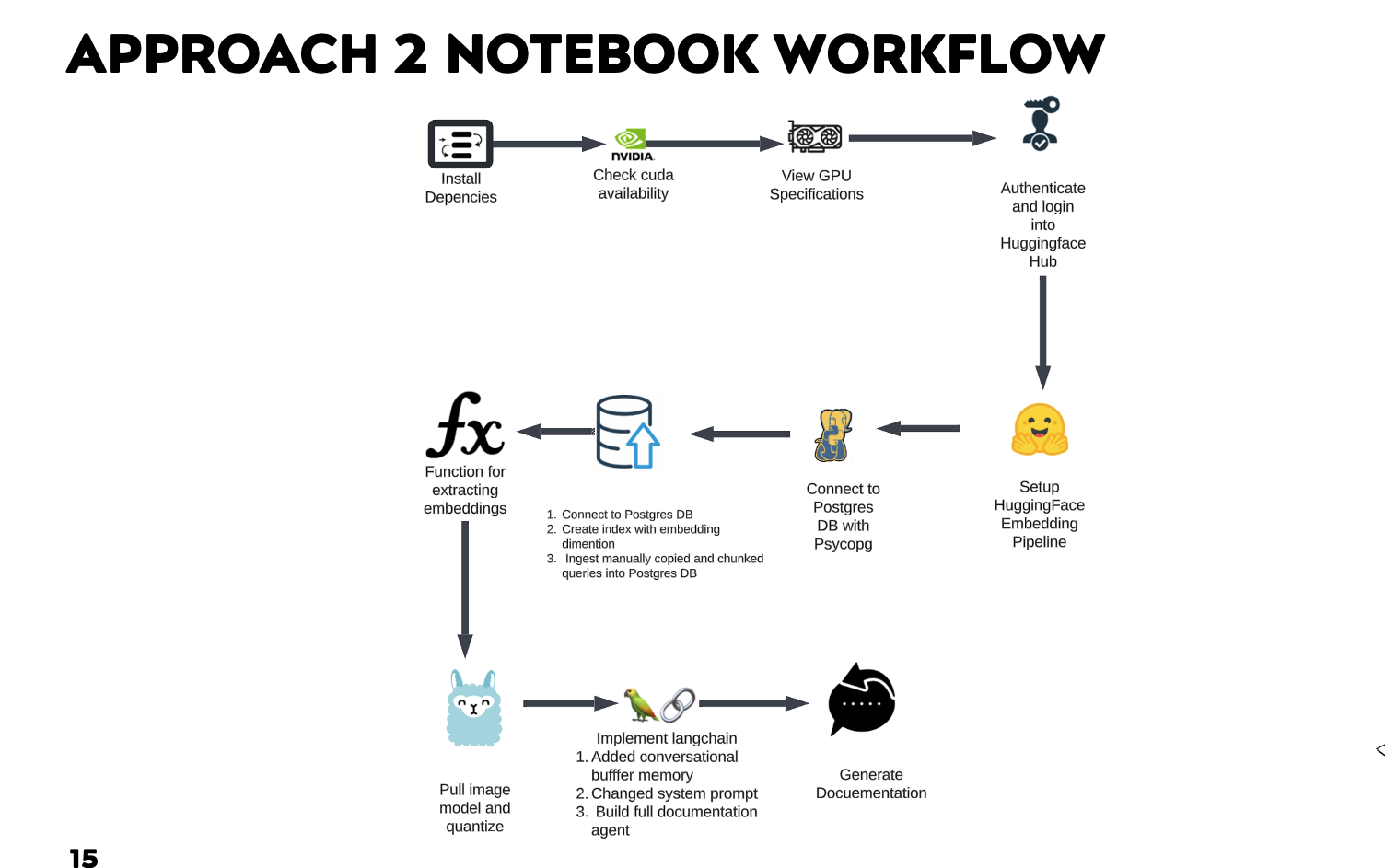
RAG Notebook Workflow
How it works (Overview)
- Embed query/metadata into vectors
- Store vectors in Postgres with pgvector (after migrating from Pinecone)
- Retrieve top-k relevant chunks by vector similarity
- Pass original query + context to LLM for documentation
Key components: LangChain, all-MiniLM-L6-v2 embeddings, dynamic chunk retrieval in Postgres.

Response after system prompt
4.3. Approach 3: Fine-Tuning the LLM
Conceptual approach of fine-tuning an LLM on dbt queries for domain-specific accuracy (not implemented).
- Anticipated challenges: data preparation, maintenance, risk of overfitting
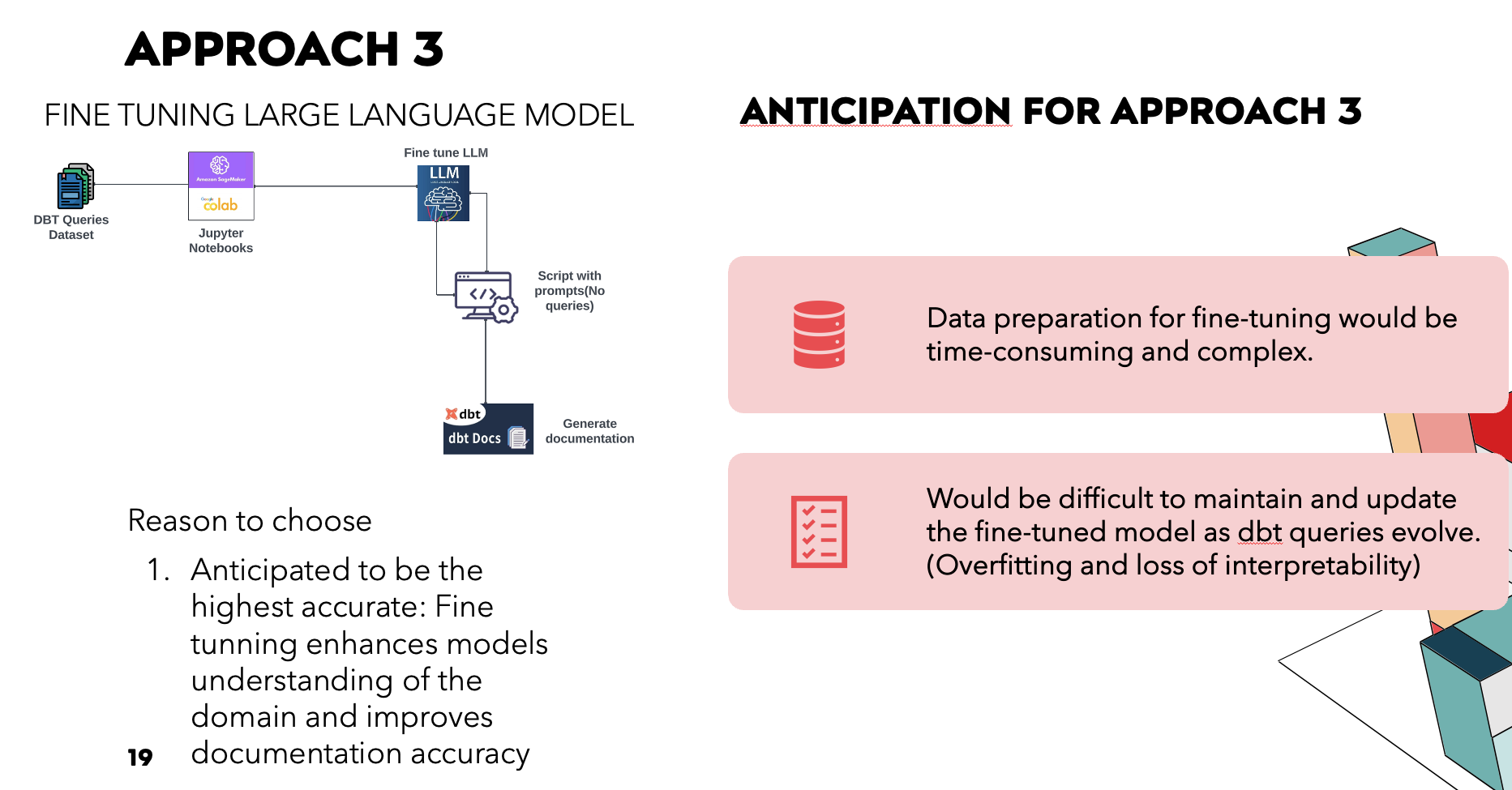
Fine-tuning LLM conceptual diagram
5. Project Deliverables
- Detailed documentation of project (PDFs/Word) files
- Three Jupyter notebooks (two implemented) showcasing each approach
- Project presentation for non-technical audiences
Conclusion and Learnings
During my internship at VRT, I not only deepened my technical expertise in both dbt and Large Language Models, but also learned the power of collaboration and continuous improvement. By iteratively refining prompt designs, embedding strategies, and retrieval workflows, always incorporating feedback from the VRT data engineers, I gained a practical understanding of how to balance model capabilities with real world constraints like token limits and GPU memory. Experimenting on Google Colab and AWS SageMaker taught me to troubleshoot performance bottlenecks in real time, while migrating from Pinecone to a Postgres + pgvector solution reinforced best practices in cost efficiency and data security. Leveraging LangChain and sentence transformer embeddings expanded my skill set in modular pipeline design and semantic search. Above all, this project underscored the importance of clear communication: translating complex SQL transformations into user friendly documentation and iteratively validating those explanations with my teammates, not only improved the end product but also strengthened my adaptability, problem-solving, and teamwork key lessons I'll carry forward into any future data engineering challenge.
Final Presentation
View Document
Final Presentation