Guided Hands on Project: Formula 1 Data Engineering with Azure Databricks, ADF, and Unity Catalog
Comprehensive data engineering project analyzing Formula 1 data with Azure Databricks and Azure Data Factory.
Microsoft AzureAzure DatabricksApache SparkAzure Data FactoryUnity Catalog
Project Overview
A comprehensive data engineering project analyzing Formula 1 data, starting with the construction of a core data pipeline using Azure Databricks and Azure Data Factory. The project then progressed to a modern data governance implementation in a focused mini-project, refactoring the solution to use a medallion architecture and Unity Catalog.
Phase 1: Building the Core Data Pipeline
The initial phase of the project focused on building a robust, end-to-end pipeline to process and analyze historical Formula 1 data. The primary objective was to ingest raw data files (CSVs and JSONs), perform necessary transformations such as cleaning, joining, and aggregating, and load the results into Delta tables. This entire workflow, from data ingestion to final table creation, was automated and orchestrated using Azure Data Factory pipelines, which executed a series of interconnected Databricks notebooks.
Phase 2: Mini-Project - Modernization with Medallion Architecture and Unity Catalog
Building upon the foundational pipeline, the second phase involved a mini-project to modernize the architecture and implement advanced data governance. Using the same Formula 1 dataset, I refactored the data flow to follow the medallion architecture, structuring the data into Bronze (raw), Silver (cleansed), and Gold (aggregated for analytics) layers. This phase was centered around the adoption of Unity Catalog to establish a unified governance solution, providing centralized access control, data discovery, and lineage tracking for the entire data lakehouse.
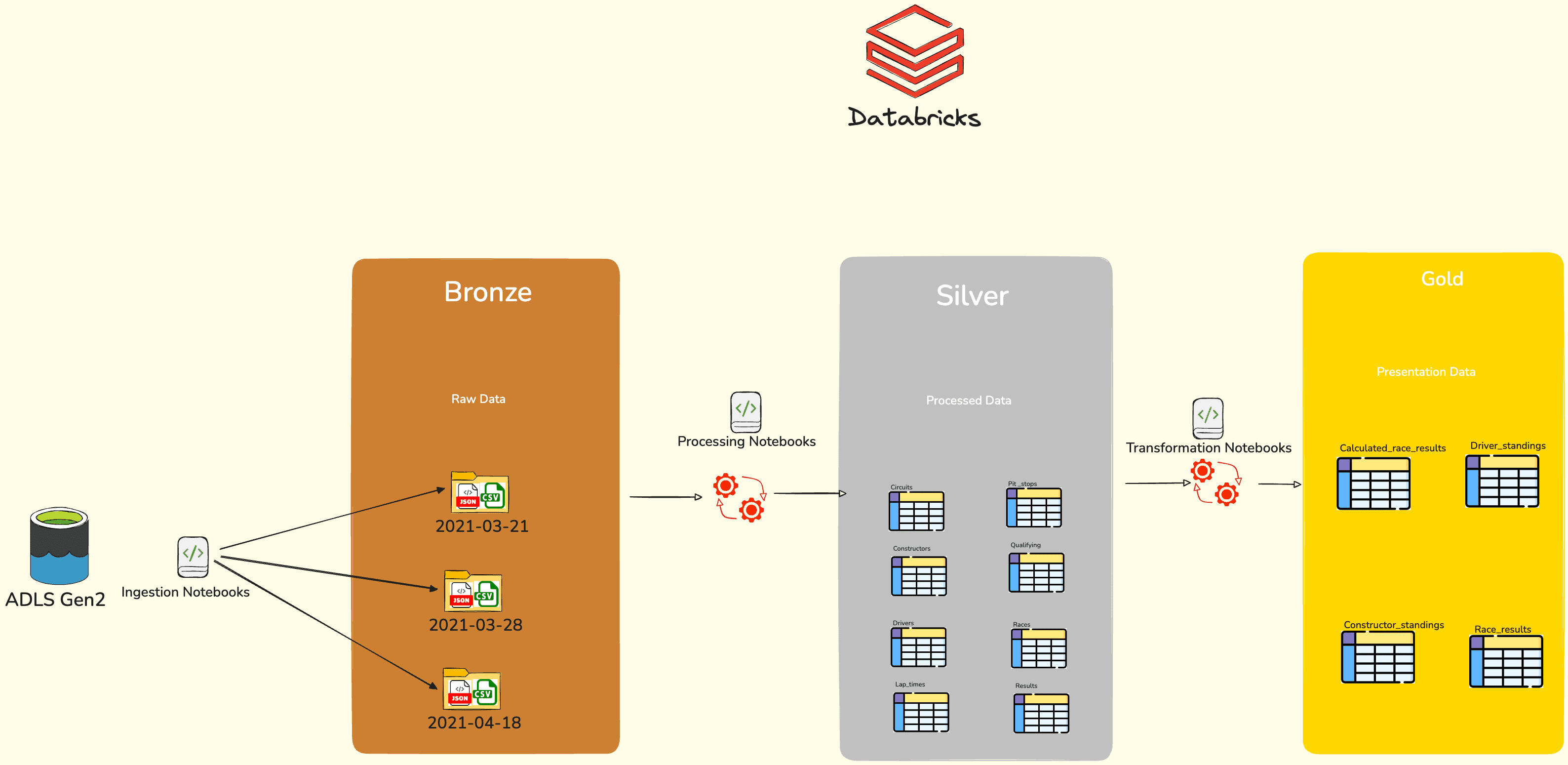
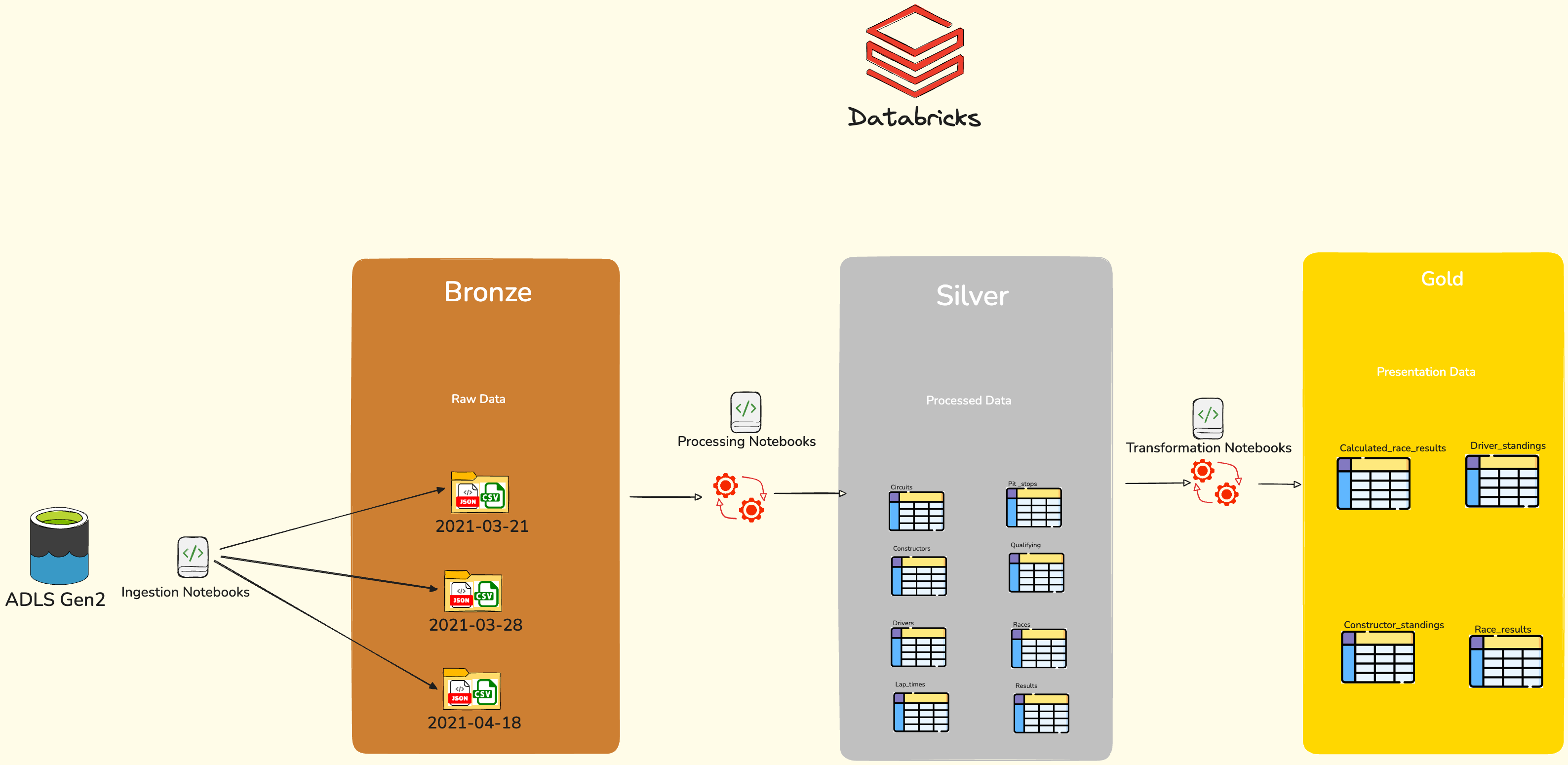
Medallion Architecture diagram
Bronze Layer: 2021-03-21(All historical data of formula 1 ingested fully up to that date), 2021-03-28 & 2021-04-18(Next race events ingested incrementally)
Silver Layer: (Process tables like Circuits, Constructors, Drivers, Pit_stops, Lap_times, Qualifying, Races and Results)
Gold Layer: Presentation ready results like Driver_points, Driver_standings, Constructor_standings and Race_results
Problems and Objectives
Problem
After learning Azure Databricks in an academic setting, a lack of practical application had led to a skill gap. As I re-entered the job market, I needed a comprehensive, hands-on project to not only refresh my core data engineering skills but also to become proficient in the latest industry-standard practices like modern data governance and architecture patterns.
Objectives
Refresh Foundational Skills: Re-establish a strong understanding of Azure Databricks, PySpark, Spark SQL, and pipeline orchestration with Azure Data Factory
Implement a Modern Data Architecture: Gain practical experience building a data lakehouse using the medallion (Bronze, Silver, Gold) architecture
Refresh Data Governance Knowledge: Learn and apply Unity Catalog to manage data access, security, and lineage in a real-world scenario
Showcase an End-to-End Solution: Create a complete portfolio piece demonstrating skills across the entire data engineering lifecycle
Hands-on Pipeline Orchestration
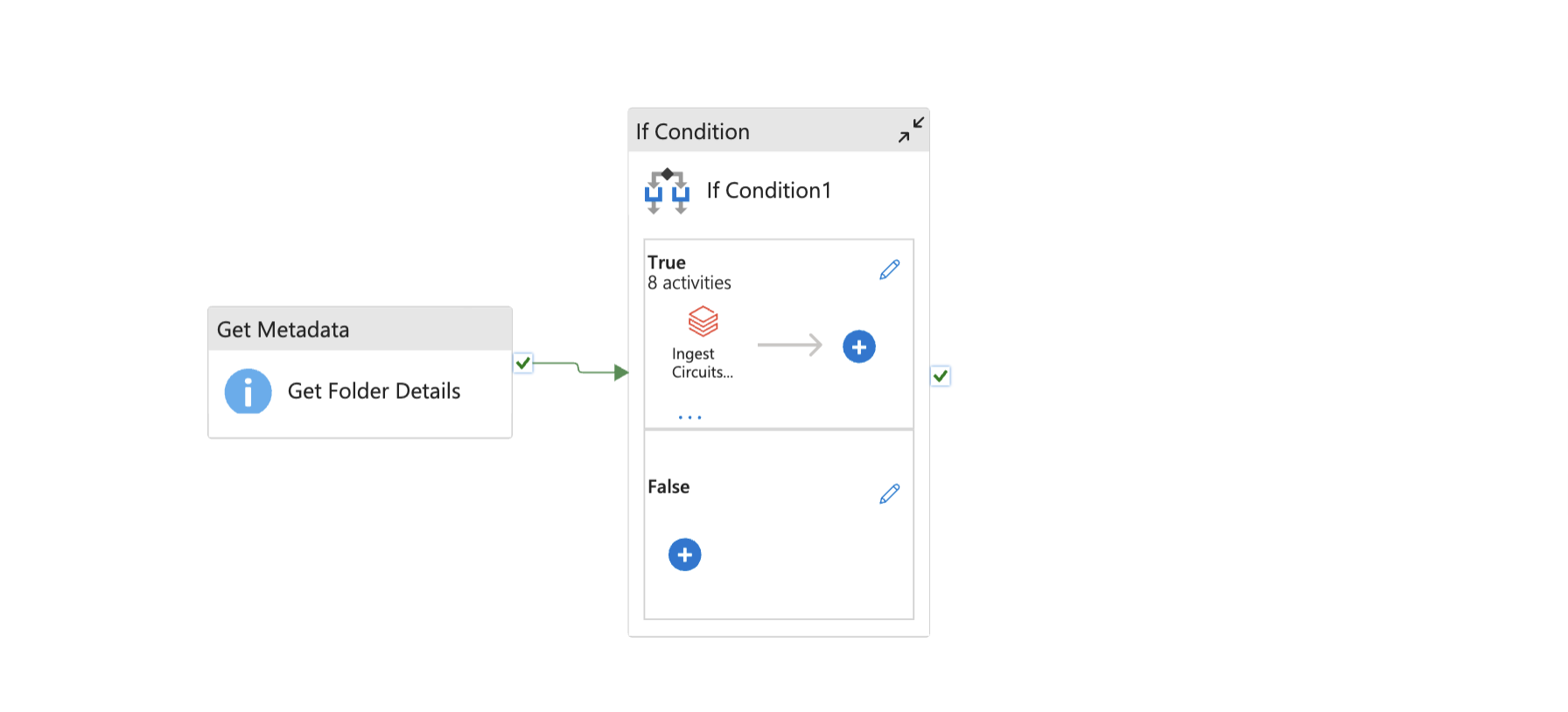
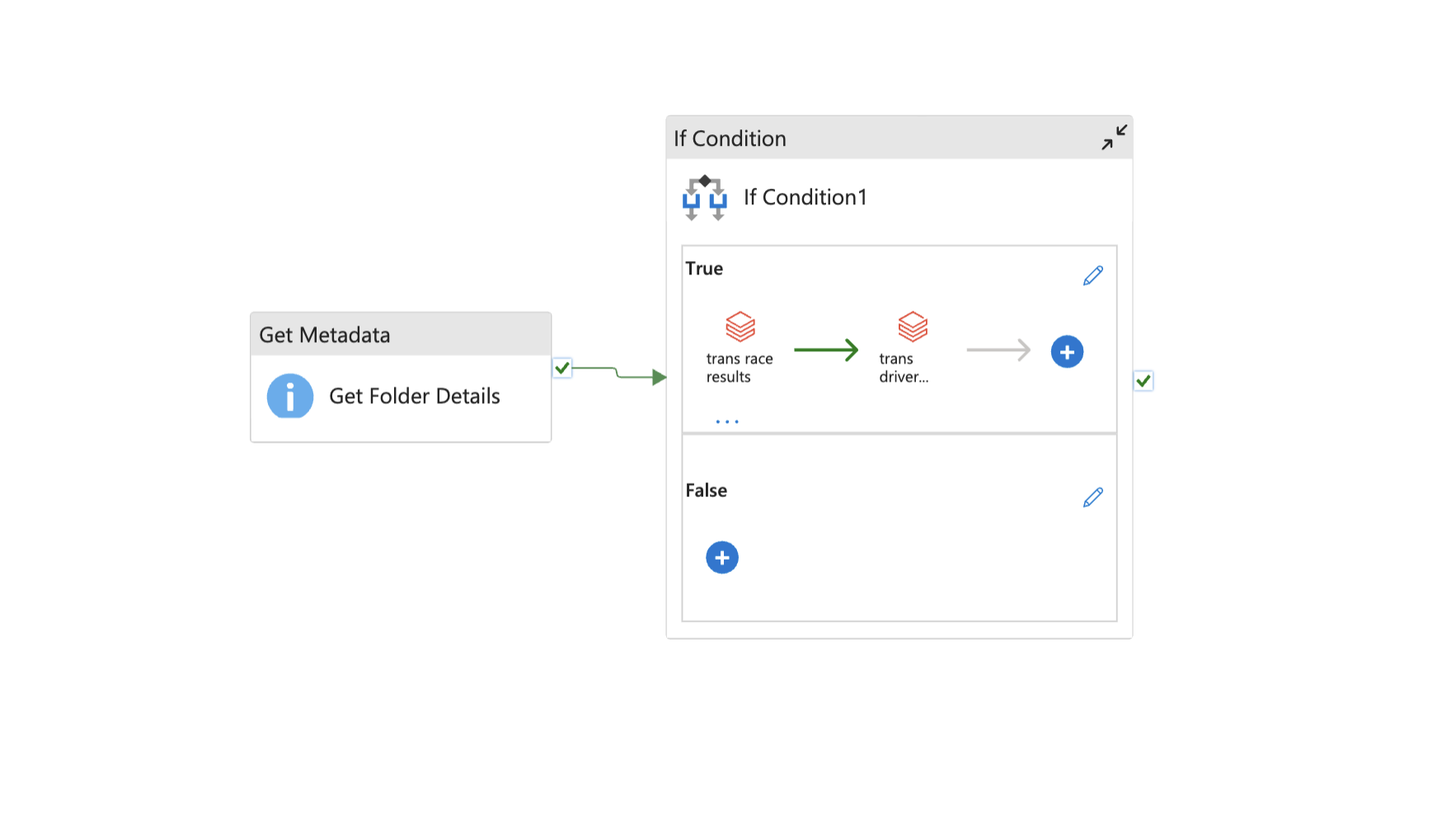
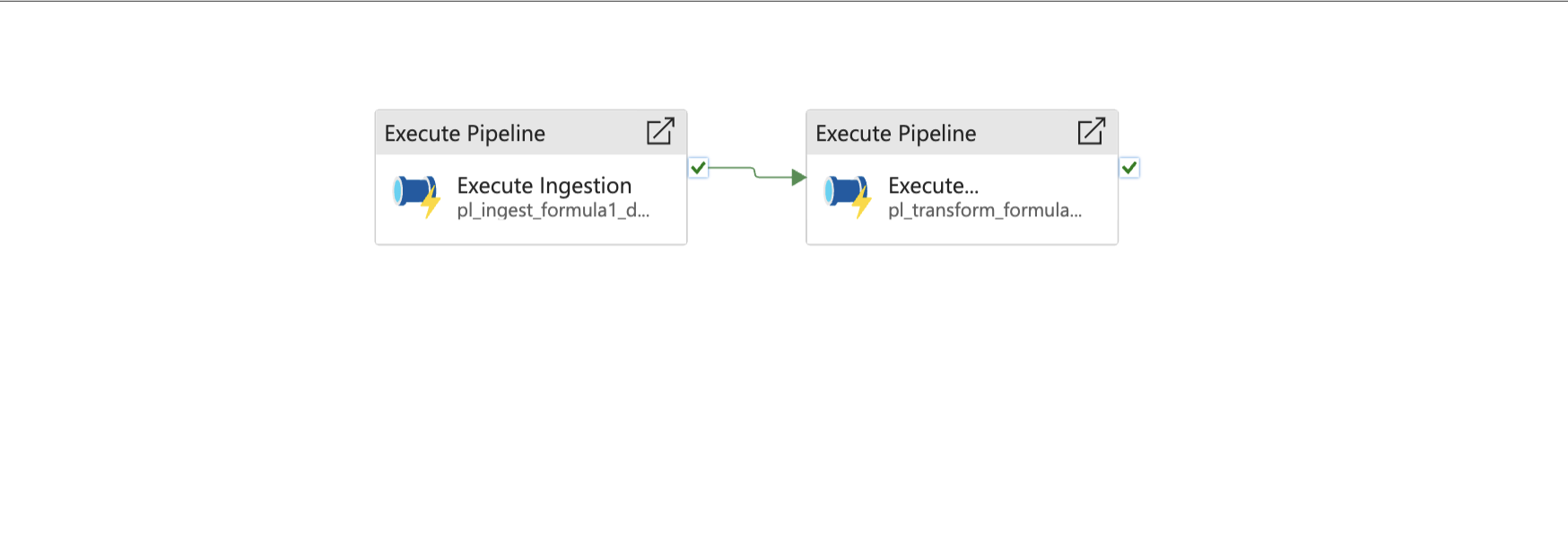
I put the course material into practice by ingesting different file types as data sources and using both PySpark and Spark SQL to perform transformations, including complex joins and window functions for driver rankings. A major part of this module was learning automation, where I successfully built and configured the Azure Data Factory workflow. This involved passing parameters to the pipeline and setting up triggers to manage both historical and incremental data loads, demonstrating a real-world use case.
Ingestion Pipeline
Transformation Pipeline
Execution/Process Pipeline
Applying Governance with Unity Catalog
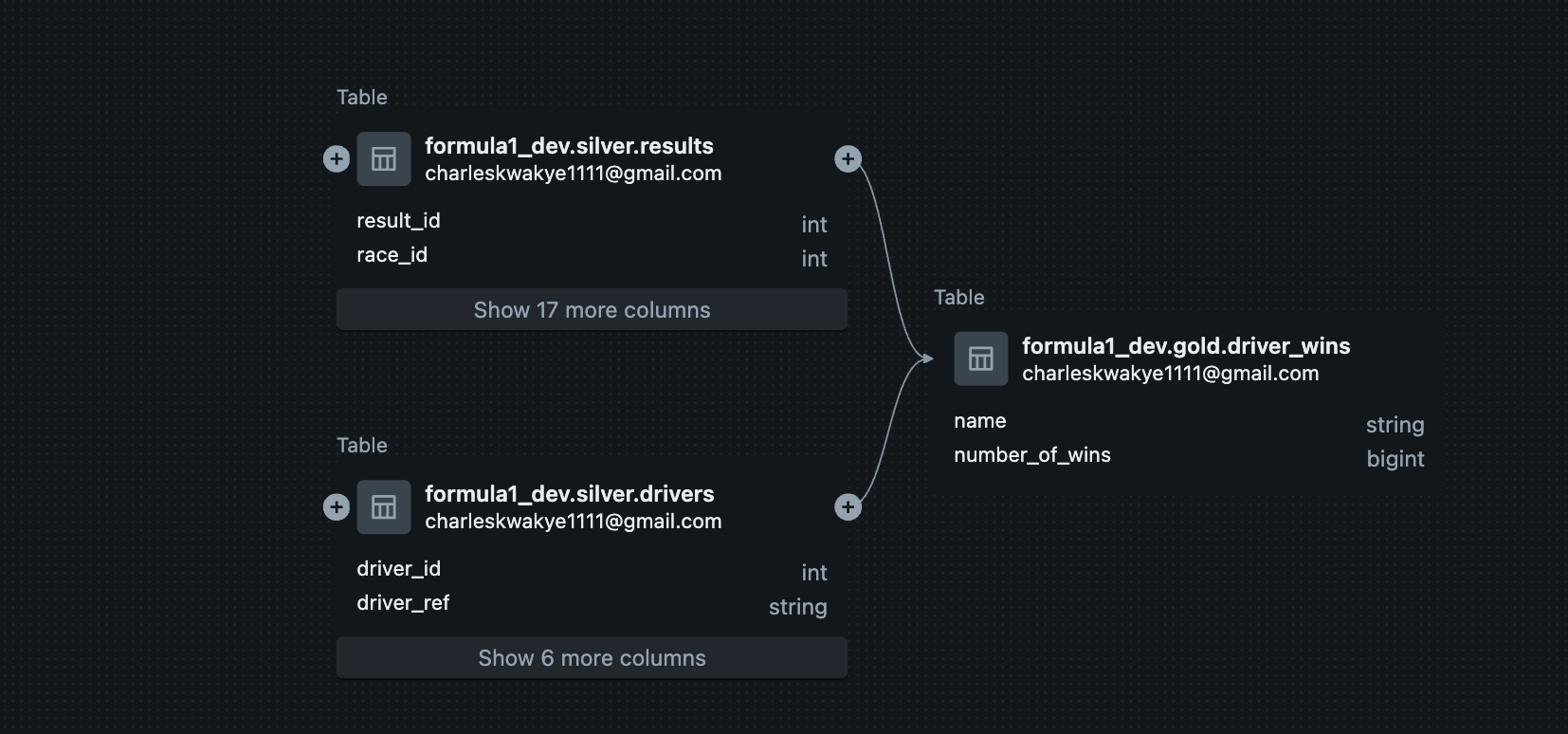
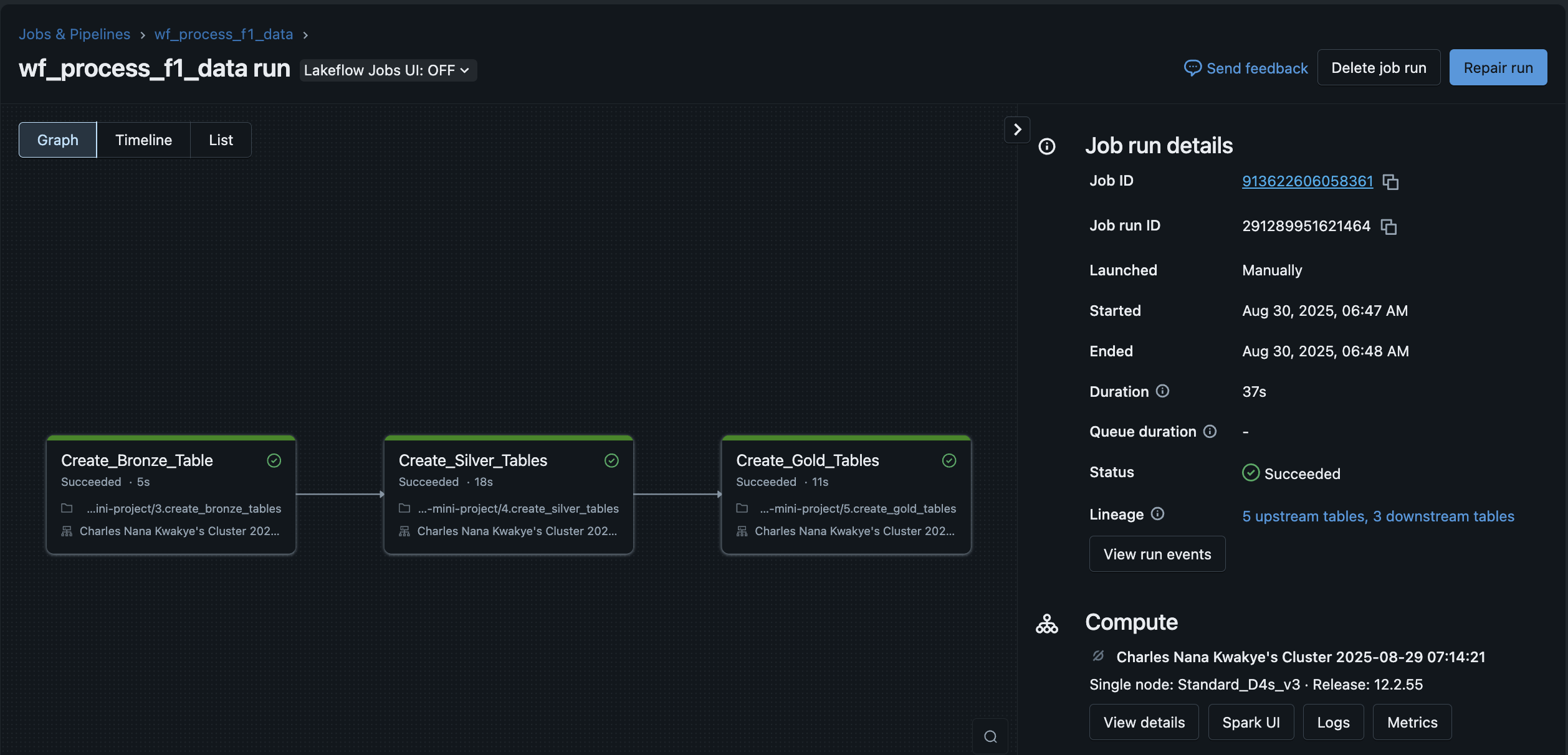
In the project's modernization phase, I gained hands-on experience structuring data into the Bronze, Silver, and Gold layers. The practical integration of Unity Catalog was a key learning outcome. I was tasked with the end-to-end configuration, from setting up the metastore and creating external locations to managing tables through Unity's three-level namespace. This exercise gave me direct exposure to critical governance capabilities like auditing data access and visualizing data lineage.
An Example of lineage for the Mini project
A databricks workflow run successfully showing the tables created
Challenges and Solutions
A key challenge arose when working with the Unity Catalog-enabled cluster in Shared access mode. My code, which initially used the PySpark command spark.catalog.tableExists(), failed with a py4j.security.Py4JSecurityException.
Solution:
I diagnosed the issue to be the security model of the shared cluster, which restricts low-level Java calls made by certain PySpark APIs. To resolve this, I refactored the logic to use a pure SQL-based check instead. By executing a SQL query to check for the table's existence, I was able to achieve the same outcome while remaining compliant with the cluster's security constraints. This experience was a practical lesson in platform-specific limitations and the importance of adapting code for different execution environments.
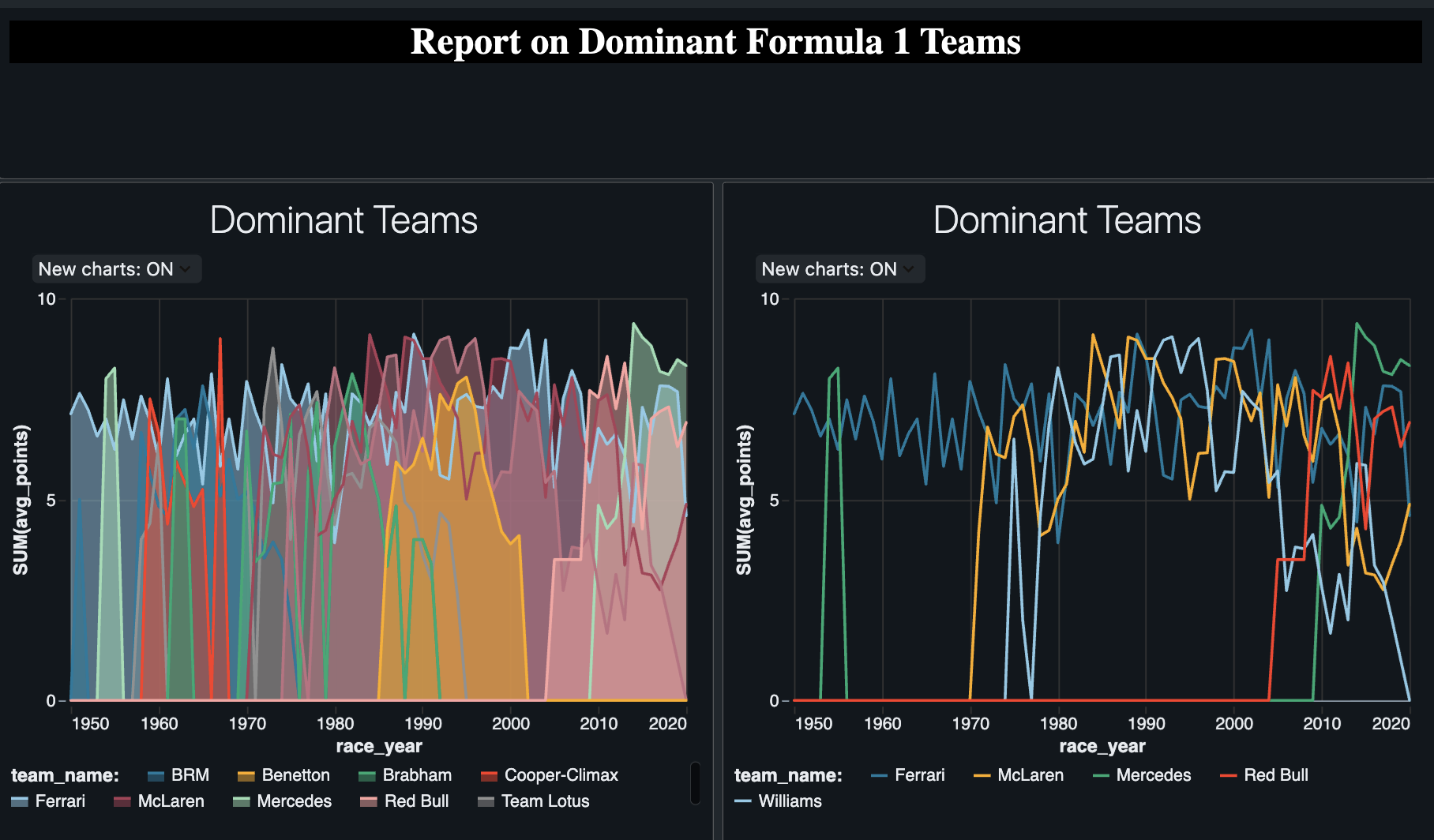
Project Outcome and Visualization
The project culminated in a set of analysis-ready tables in the Gold layer. Using this data, I built an interactive dashboard in Databricks to visualize key performance indicators, such as the most dominant drivers and constructors in Formula 1 history. This final output successfully demonstrates the application of skills across the entire data pipeline, from raw data to actionable insight.