This project is an end-to-end Machine Learning pipeline designed to predict individual motor insurance claim severity using a dataset of over 70,000 Belgian insurance records. I developed a robust system that cleans raw data, performs advanced feature engineering—such as target encoding for high-cardinality vehicle models—and evaluates seven different regression architectures. The final solution utilizes a Random Forest model optimized for Mean Absolute Percentage Error (MAPE) to ensure high accuracy for individual claim predictions. To bridge the gap between development and production, I integrated MLflow for experiment tracking, hosted the versioned model on the Hugging Face Hub, and deployed a real-time prediction interface via Streamlit.
The Problem
Insurance companies need to predict claim severity (the expected cost of a claim) to set appropriate premium prices, allocate reserves for future claims, and identify high-risk policies.
The Solution
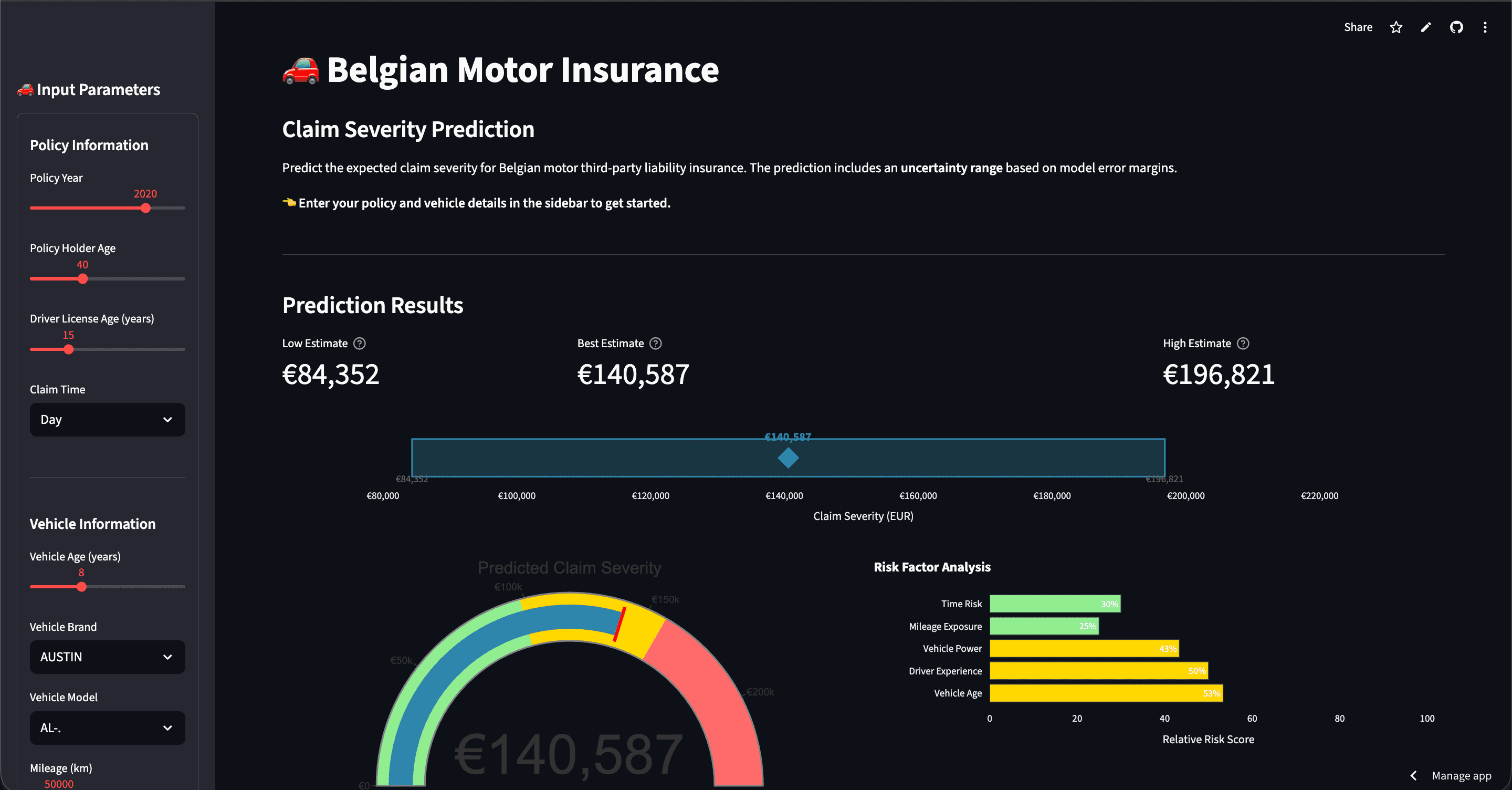
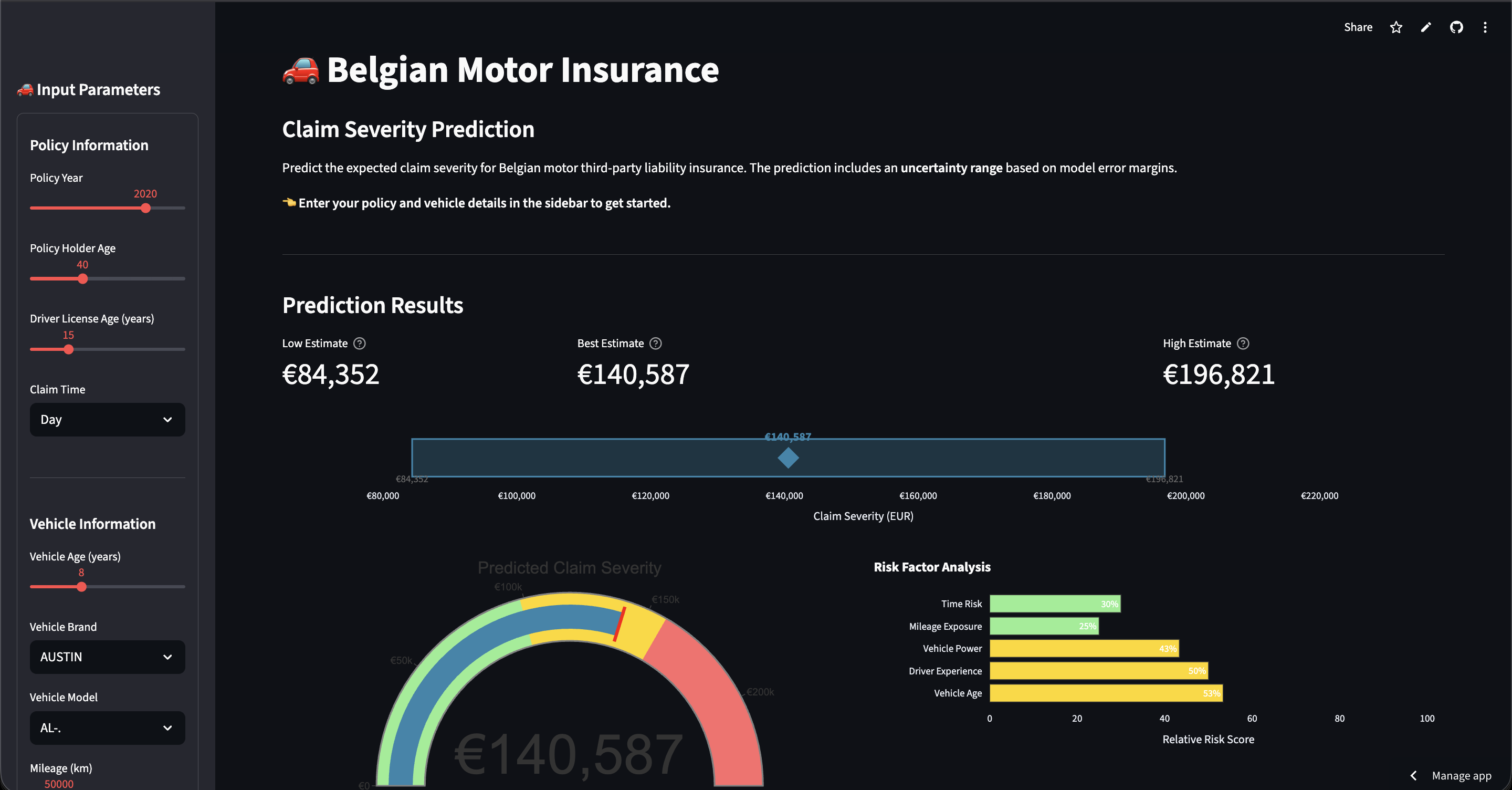
A Random Forest model trained on 70,000+ Belgian motor insurance claims, optimized for individual claim accuracy (lowest MAPE) while maintaining strong overall performance.
Architecture
The architecture consists of two main components: Data & Training Pipeline and Production Deployment. The data flows from the Belgian MTPL dataset through Jupyter notebooks for processing, with MLflow tracking experiments and Hugging Face Hub storing models. The production deployment uses Streamlit Cloud to serve predictions to end users.
Data Flow
Source: Belgian MTPL (Motor Third-Party Liability) insurance dataset (beMTPL16.rda)
scikit-learn: ML algorithms, preprocessing, pipelines
XGBoost: Gradient boosting
category_encoders: Target encoding for high-cardinality features
pyreadr: Read R data files (.rda)
MLOps
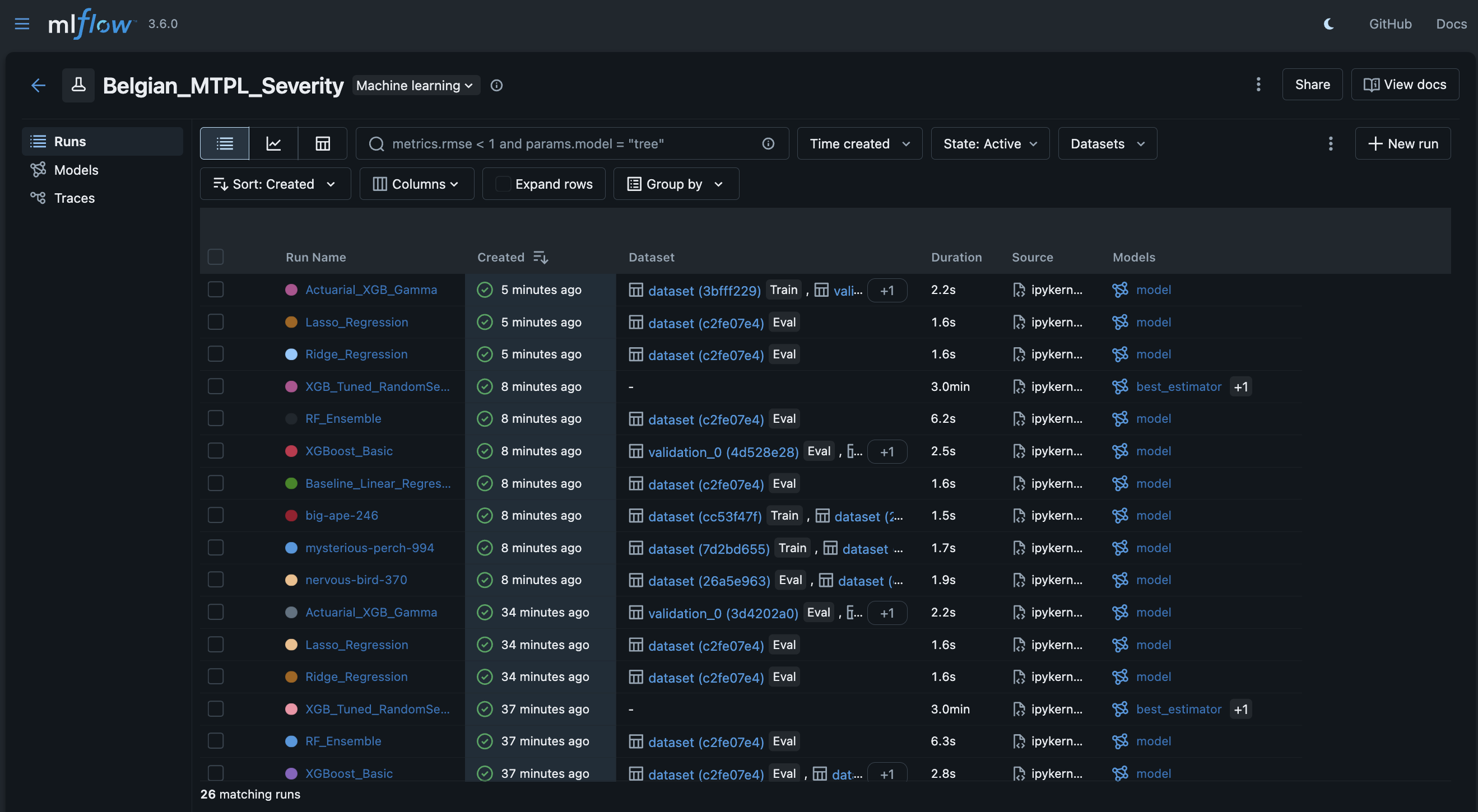
MLflow: Experiment tracking, metric logging
Hugging Face Hub: Model registry and artifact storage
joblib: Model serialization
Deployment
Streamlit: Interactive web application
Streamlit Cloud: Free hosting platform
Dataset
Belgian MTPL Insurance Data (beMTPL16) contains 70,791 insurance records from the period 2004-2016. The target variable is claim severity (amount in EUR).
Features Used
policy_year: Year the policy was issued
vehicle_age: Age of the vehicle in years
policy_holder_age: Age of the policy holder
driver_license_age: Years since license obtained
vehicle_brand: Vehicle manufacturer (100+ unique)
vehicle_model: Vehicle model (1000+ unique)
mileage: Vehicle mileage in km
vehicle_power: Engine power in HP
catalog_value: Vehicle catalog price in EUR
claim_time: Day/Night (engineered from timestamp)
Feature Engineering
A key part of the project was converting raw claim time to Day/Night categories using a custom function. Night was defined as 20:00 - 06:00, and Day as 06:00 - 20:00.
Actuarial XGBoost: Gamma Loss - Best for portfolio risk
Preprocessing Pipeline
Numeric features use StandardScaler for normalization. Low-cardinality categoricals use OneHotEncoder, while high-cardinality categoricals use TargetEncoder to handle the 1000+ unique vehicle models.
Why Random Forest?
For individual claim predictions, Random Forest achieves the lowest MAPE (Mean Absolute Percentage Error). It provides the best accuracy on individual claim amounts because: the ensemble of decision trees reduces overfitting, it handles mixed feature types well, and it is robust to outliers via log-transformation. Note: For portfolio-level reserve calculations where large claims matter more, the Actuarial XGBoost (Gamma loss) model achieves lower RMSE.
Model Performance
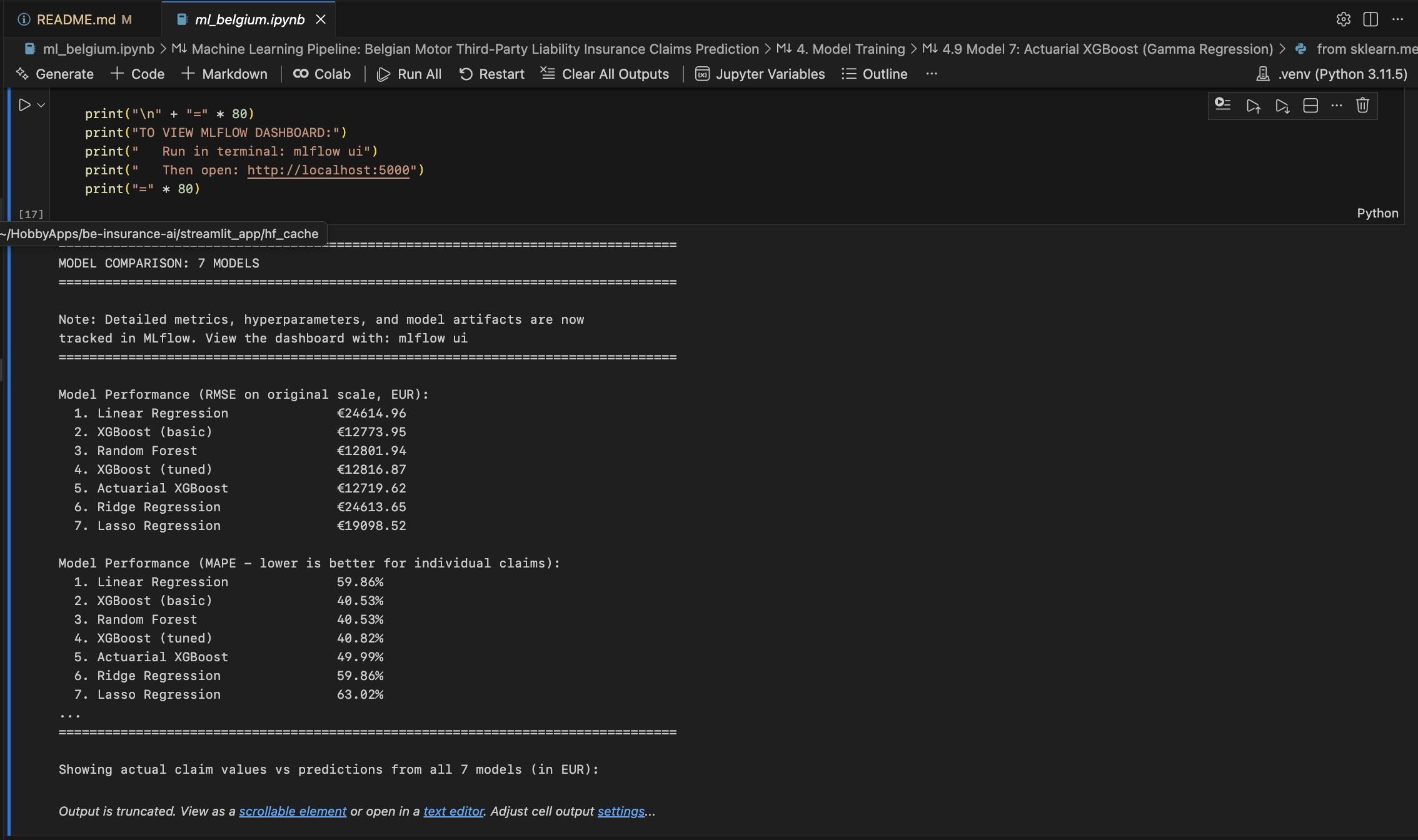
Comparison Results across all 7 models trained:
Linear Regression: RMSE €24,615, MAPE 59.86%
Ridge Regression: RMSE €24,614, MAPE 59.86%
Lasso Regression: RMSE €19,099, MAPE 63.02%
Random Forest: RMSE €12,802, MAPE 40.53% (BEST for individual claims)
XGBoost (Basic): RMSE €12,774, MAPE 40.53%
XGBoost (Tuned): RMSE €12,817, MAPE 40.82%
Actuarial XGBoost: RMSE €12,720, MAPE 49.99% (Best for portfolio risk)
Best model selected by lowest MAPE for individual claim accuracy.
Deployment
Hugging Face Hub
The trained model and artifacts are stored on Hugging Face Hub for version control, easy access (download with one line of code), and collaboration.
Streamlit Cloud
The web app is deployable to Streamlit Cloud with zero infrastructure (no servers to manage), auto-scaling, and free tier perfect for portfolio projects.
Screenshots
ML Notebook - Model Training - Training 7 different models with MLflow tracking
MLflow - Experiment Tracking - Compare model performance across experiments
Clone the repository: git clone https://github.com/charleskwakye/be-insurance-ai.git && cd be-insurance-ai. Create virtual environment: python -m venv venv. Activate on Windows: venv\Scripts\activate or source venv/bin/activate on Mac/Linux. Install dependencies: pip install -r requirements.txt
Train the Model
Run ml_belgium.ipynb in Jupyter or VS Code. Run all cells sequentially. View experiments in MLflow UI: mlflow ui. The best model will be uploaded to Hugging Face Hub.
Run the Web App
cd streamlit_app && pip install -r requirements.txt && streamlit run app.py
Environment Variables
Copy .env.example to .env and edit to add your HF_TOKEN for Hugging Face authentication.